对抗 QQ 音乐网页端的请求签名 (zzc + ag-1)
今日发现 QQ 音乐的网页端上线了个新的签名算法,特点为签名前缀为 zzc 字符(简称 zzc 签名)。
与上个版本的 zzb 签名一样用了类似 JS-VMP 的虚拟化技术,但是实现有所不同,于是花了点时间分析。
原始虚拟化的代码可以在 vendor.chunk.b6ee1532c576a0967fed.js 获取(archive.org 备份)。
QQ 音乐网页端请求签名分析系列文章:
- QQ 音乐网页端的请求签名分析 (zza) - 2020.03
- QQ 音乐网页端的请求签名分析 (zzb) - 2021.07
- 对抗 QQ 音乐网页端的请求签名 (zzc) - 2024.07
上手试探
首先在浏览器的调试器进行尝试,看相同的输入是否会产生相同的输出。
如果每次都是一致,那么就可以将这些数据做测试向量了。
※ 本文使用基于 Chromium 的 Brave 浏览器做调试,火狐或其它浏览器应该都大差不差。
寻找签名函数
首先使用浏览器的开发者工具找到下述片段:
| |
※ 如果该文件更新过,可能会有些许不同。
可以看到签名来自上述片段的第 3 行的 o 方法,因此在该行下断点,然后刷新页面。
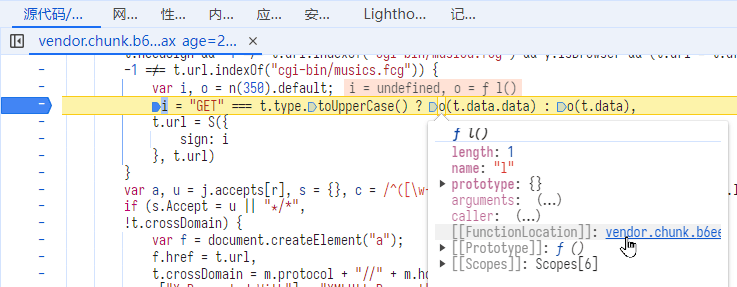
在开发者工具下断点,并访问来源。
断下后就可以主动调用观察一下输出了:
o('123') // 'zzcec1b555gzqzg7laztguyjl2bu20r6x1w50c55f60'
o('123') // 'zzcec1b555gzqzg7laztguyjl2bu20r6x1w50c55f60'
o('hello world') // 'zzcfb3415bc4nfoxmd9uik71mkomtubjfjp141a1cbbcc'
o('jixun.uk') // 'zzcf47b78apso27mjjbbzgbof0szikfkvyqc7fc3a2b5'
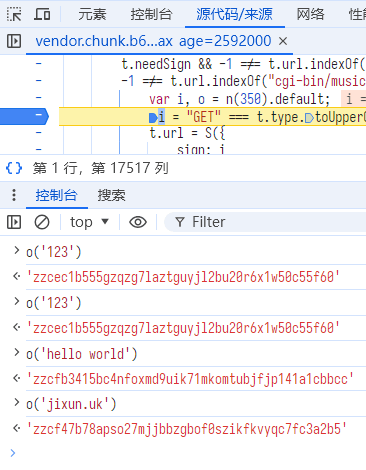
主动调用来观察签名特性。
可以发现这个签名算法的输出长度不固定,但是相同输入会产生相同的输出。
抠代码
o 方法来自 n(350)。
透过开发者工具查看该变量,可以点击 [[FunctionLocation]] 抵达该虚拟化后的函数地址:
return function l() {
for (var f, p, d = [a, s, t, this, arguments, l, n, 0], h = void 0, g = e, v = []; ; )
向上找到对应的 function(e, t, n) { 和结束点,然后抠出来备用吧。
其中 e, t, n 分别为 module, exports, require 这三个变量,可以顺便在 IDE 里将这三个还原。
虚拟机初始化 world 的时候同时引入了 n(80),用于获取当前全局环境,即浏览器的 window 变量:
function(e, t) {
var n;
n = function() {
return this
}();
try {
n = n || new Function("return this")()
} catch (r) {
"object" === typeof window && (n = window)
}
e.exports = n
}
提取字节码
既然是虚拟机,自然有自己的字节码。
虚拟机最外层用了 base64 解码到 int8 数组,但是其虚拟机的内部实现并不是单纯的利用 int8 类型,有些值的取值范围更大,因此还需要解码处理。
将解码的片段 n = a(e) 进行分析并重写后的代码如下:
const VM_CODE = 'Xh7YHJgHOBoIAE ... 自行补充 ...';
function fixSign(value: number): number {
return (value >> 1) ^ -(1 & value);
}
function decodeVM(vmCode: string): number[] {
const decoded: number[] = [];
const bytes = Buffer.from(vmCode, 'base64');
let buffer = 0;
let shifts = 0;
for (const byte of bytes) {
buffer += (byte & 0x7f) << shifts;
if ((byte & 0x80) != 0) {
shifts += 7;
continue;
}
buffer = fixSign(buffer);
decoded.push(buffer);
buffer = 0;
shifts = 0;
}
return decoded;
}
虚拟机架构
首先就是分析虚拟机的各个变量分别是什么含义:
var n = a(e)
, o = function(e, t, a, s, c) {
return function l() {
for (var f, p, d = [a, s, t, this, arguments, l, n, 0], h = void 0, g = e, v = []; ; )
整理一番后:
var vm_code = decodeVM(VM_CODE)
, createVM = function(entrypoint, params, world, initialData, errorReportCallback) {
return function vm_runtime() {
var tempArgs; /* f */
var tempArgCount; /* p */
var stack /* d */ = [world, initialData, params, this, arguments, vm_runtime, vm_code, 0];
var fnCtx /* h */ = void 0;
var pc /* g */ = entrypoint; // pc 为当前执行的指令的地址。
var tryCatchHandlers /* v */ = [];
for (; ; ) // while(true)
其中:
fnCtx的值恒定为undefined(fnCtx的名称有点不对,但是都分析完了,就不改了)tempArgs与tempArgCount为建立新的回调函数时绑定变量(scope块的变量共享),新的函数通过params访问。vm_code也导出到了虚拟机可访问的内存环境中哦。stack名称改为mem可能更适合?都一个意思啦,用来在执行时存储临时数据的。
反编译
毕竟是“全新”的虚拟架构,如果能将字节码反编译到指令的话,比啃字节码要方便很多。
观察源码可以发现该文件包含了两个虚拟机的实现,但是这两个虚拟机实际上都是同一套解释器,因此挑一个顺眼的来魔改就行。
需要注意,虚拟机用了很多 stack[++pc] = stack[++pc] ... 的代码,注意读取下一个字节码的顺序不能搞错。
因为不是基于传统意义上的堆栈(入栈出栈传递参数),因此从字节码读取的指针可以直接介入到生成的代码里。
准备工作
使用 pnpm init 初始化,然后安装一些基本的依赖:
pnpm i -D typescript ts-node @types/node
# 可选
pnpm i -D prettier
实现反编译器
找到虚拟机的字节码分发器,改写成反编译器:
反编译器代码
// VM2 反编译
// Author: Jixun - https://jixun.uk/posts/2024/qqmusic-zzc-sign/
//
// License: CC By-SA 4.0
// See: https://creativecommons.org/licenses/by-sa/4.0/
export function decompileVM2(code: number[], entrypoint: number, explored = new Set<number>(), actions: string[] = []) {
let pc = entrypoint;
let opcode = 0;
const loc = (addr: number) => `loc_${addr.toString(10).padStart(4, '0')}`;
const names = ['world', 'initialData', 'params', 'ctx', 'arguments', 'vm_runtime', 'vm_code'];
const log = (message: string) =>
actions.push(` ${message}`.replace(/stack\[([0-6])]/g, (_, x) => `stack_${x}.${names[x]}`));
const logAddr = () => actions.push(`${loc(pc)}: # op:${opcode}`);
function condJump() {
// pc += stack[code[++pc]] ? code[++pc] : code[(++pc, ++pc)];
const locToCheck = code[pc + 1];
const offsetLocSuccess = pc + code[pc + 2];
const offsetLocFail = pc + code[pc + 3];
log(`if (stack[${locToCheck}]) {`);
log(` goto: ${loc(offsetLocSuccess + 1)}`);
log(`} else {`);
log(` goto: ${loc(offsetLocFail + 1)}`);
log(`}`);
decompileVM2(code, offsetLocSuccess, explored, actions);
decompileVM2(code, offsetLocFail, explored, actions);
}
while (true) {
opcode = code[++pc];
logAddr();
if (explored.size > 10000) {
log('too many addresses');
return;
}
if (explored.has(pc)) {
log(`// EXPLORED PC ${loc(pc)}`);
return actions;
}
explored.add(pc);
if (opcode === undefined) {
log('no opcode here');
return;
}
switch (opcode) {
case 0:
// 11, 12, 9
// stack[code[++pc]] = new stack[code[++pc]](stack[code[++pc]]);
log(`.ctor = stack[${code[pc + 2]}]`);
log(`stack[${code[pc + 1]}] = new.ctor(stack[${code[pc + 3]}])`);
pc += 3;
break;
case 1: {
const v = code[++pc];
log(`RETURN stack[${v}]`);
return;
}
case 2: {
for (let count = code[++pc]; count > 0; count--) {
log(`| PUSH_ARGS(stack[${code[++pc]}])`);
}
const fnLocation = code[pc + 1];
const nextEntry = pc + 1 + code[pc + 2];
const fnLen = code[pc + 3];
pc += 3;
log(`stack[${fnLocation}] = CREATE_FUNCTION_VM2(entrypoint=${nextEntry}, ^args, length=${fnLen})`);
break;
}
case 3:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] < stack[${code[++pc]}]`);
break;
case 4:
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}][stack[${code[++pc]}]]`);
break;
case 5:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] >= stack[${code[++pc]}]`);
break;
case 6:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] >> ${code[++pc]}`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}][stack[${code[++pc]}]]`);
break;
case 7:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] < ${code[++pc]}`);
break;
case 8:
log(`stack[${code[++pc]}] = stack[${code[++pc]}].call(fnCtx)`);
break;
case 9:
log(`stack[${code[++pc]}] = ""`);
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] = ${code[++pc]}`);
break;
case 10:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] | ${code[++pc]}`);
break;
case 11:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] & ${code[++pc]}`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}][stack[${code[++pc]}]]`);
break;
case 12:
log(`stack[${code[++pc]}] = {} // empty obj`);
break;
case 13: {
log(`stack[${code[++pc]}] = stack[${code[++pc]}] | stack[${code[++pc]}]`);
log(`stack[${code[++pc]}][stack[${code[++pc]}]] = stack[${code[++pc]}]`);
return condJump();
}
case 14:
log(`stack[${code[++pc]}] = fnCtx`);
break;
case 15:
log(`stack[${code[++pc]}] = ${code[++pc]}`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}][${code[++pc]}]`);
log(`stack[${code[++pc]}] = ${code[++pc]}`);
break;
case 16:
log(`stack[${code[++pc]}] = true`);
break;
case 17:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] === stack[${code[++pc]}]`);
break;
case 18:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] / stack[${code[++pc]}]`);
break;
case 19:
log(`stack[${code[++pc]}][stack[${code[++pc]}]] = stack[${code[++pc]}]`);
log(`stack[${code[++pc]}] = ''`);
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
break;
case 20:
log(`stack[${code[++pc]}][${code[++pc]}] = stack[${code[++pc]}]`);
log(`stack[${code[++pc]}][${code[++pc]}] = stack[${code[++pc]}]`);
log(`stack[${code[++pc]}][${code[++pc]}] = stack[${code[++pc]}]`);
break;
case 21:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] * stack[${code[++pc]}]`);
break;
case 22:
log(`stack[${code[++pc]}] = ++stack[${code[++pc]}]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}]`);
break;
case 23:
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}][stack[${code[++pc]}]]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}]`);
break;
case 24:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] << ${code[++pc]}`);
break;
case 25:
log(`stack[${code[++pc]}] = typeof stack[${code[++pc]}]`);
break;
case 26:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] | stack[${code[++pc]}]`);
break;
case 27:
log(`stack[${code[++pc]}] = ${code[++pc]}`);
break;
case 28:
log(`stack[${code[++pc]}] = stack[${code[++pc]}][${code[++pc]}]`);
break;
case 29:
log(`stack[${code[++pc]}] = ${code[++pc]}`);
log(`stack[${code[++pc]}][${code[++pc]}] = stack[${code[++pc]}]`);
log(`stack[${code[++pc]}] = ${code[++pc]}`);
break;
case 30:
log(`stack[${code[++pc]}] = stack[${code[++pc]}].call(fnCtx, stack[${code[++pc]}], stack[${code[++pc]}])`);
break;
case 31:
log(`stack[${code[++pc]}] = ${code[++pc]}`);
log(`stack[${code[++pc]}] = ${code[++pc]}`);
log(`stack[${code[++pc]}] = ${code[++pc]}`);
break;
case 32:
log(`stack[${code[++pc]}] = ${code[++pc]}`);
log(`stack[${code[++pc]}][stack[${code[++pc]}]] = stack[${code[++pc]}]`);
break;
case 33:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] === ${code[++pc]}`);
break;
case 34:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] + ${code[++pc]}`);
break;
case 35:
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
break;
case 36:
log(`stack[${code[++pc]}] = ''`);
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
break;
case 37:
log(`stack[${code[++pc]}] = stack[${code[++pc]}][${code[++pc]}]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}][${code[++pc]}]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}][${code[++pc]}]`);
break;
case 38:
log(`stack[${code[++pc]}] = ''`);
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
break;
case 39:
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}] === stack[${code[++pc]}]`);
return condJump();
case 40:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] > stack[${code[++pc]}]`);
break;
case 41:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] - stack[${code[++pc]}]`);
break;
case 42:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] << stack[${code[++pc]}]`);
break;
case 43:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] & stack[${code[++pc]}]`);
break;
case 44:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] & ${code[++pc]}`);
break;
case 45:
log(`stack[${code[++pc]}] = -stack[${code[++pc]}]`);
break;
case 46: {
for (let f = [], p = code[++pc]; p > 0; p--) {
log(`| PUSH_ARG_VM1: stack[${code[++pc]}]`);
}
const locFnLoc = code[++pc];
const locFnEntry = pc + code[++pc];
const fnLen = code[++pc];
log(`stack[${locFnLoc}] = CREATE_VM1_FN(${locFnEntry}, ^args, length=${fnLen})`);
// stack[code[++pc]] = createVM1(pc + code[++pc], f, world, initialData, errorWrapper);
// try {
// Object.defineProperty(stack[code[pc - 1]], 'length', {
// value: code[++pc],
// configurable: true,
// writable: false,
// enumerable: false,
// });
// } catch (y) {}
break;
}
case 47:
// pc += stack[code[++pc]] ? code[++pc] : code[(++pc, ++pc)];
return condJump();
// break;
case 48:
log(`stack[${code[++pc]}][${code[++pc]}] = stack[${code[++pc]}]`);
break;
case 49:
log(`stack[${code[++pc]}] = ~stack[${code[++pc]}]`);
break;
case 50:
log(`stack[${code[++pc]}] = stack[${code[++pc]}].call(stack[${code[++pc]}])`);
break;
case 51:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] ^ stack[${code[++pc]}]`);
break;
case 52:
log(`stack[${code[++pc]}] = ++stack[${code[++pc]}]`);
break;
case 53:
log(`stack[${code[++pc]}] = false`);
break;
case 54:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] >>> ${code[++pc]}`);
break;
case 55:
log(`stack[${code[++pc]}][${code[++pc]}] = stack[${code[++pc]}]`);
log(`stack[${code[++pc]}] = ${code[++pc]}`);
log(`stack[${code[++pc]}][${code[++pc]}] = stack[${code[++pc]}]`);
break;
case 56:
log(`stack[${code[++pc]}] = Array(${code[++pc]})`);
break;
case 57:
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}][${code[++pc]}] = stack[${code[++pc]}]`);
break;
case 58:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] % stack[${code[++pc]}]`);
break;
case 59:
log(`stack[${code[++pc]}] = stack[${code[++pc]}][stack[${code[++pc]}]]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}][${code[++pc]}]`);
break;
case 60:
log(`stack[${code[++pc]}] = stack[${code[++pc]}][${code[++pc]}]`);
log(`stack[${code[++pc]}] = ${code[++pc]}`);
break;
case 61:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] - ${code[++pc]}`);
break;
case 62:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] + stack[${code[++pc]}]`);
break;
case 63:
log(`stack[${code[++pc]}] = !stack[${code[++pc]}]`);
break;
case 64:
log(`stack[${code[++pc]}][stack[${code[++pc]}]] = stack[${code[++pc]}]`);
break;
case 65: {
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
for (let p = code[++pc]; p > 0; p--) {
log(`| PUSH_VM1_ARG: stack[${code[++pc]}]`);
}
const locFnLoc = code[++pc];
const locFnEntry = pc + code[++pc];
const fnLen = code[++pc];
log(`stack[${locFnLoc}] = CREATE_VM1_FN(${locFnEntry}, ^args, length=${fnLen})`);
log(`stack[${code[++pc]}][stack[${code[++pc]}]] = stack[${code[++pc]}]`);
break;
}
case 66:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] - 0`);
break;
case 67:
log(`stack[${code[++pc]}] = stack[${code[++pc]}].call(stack[${code[++pc]}], stack[${code[++pc]}])`);
break;
case 68:
log(`stack[${code[++pc]}] = stack[${code[++pc]}][${code[++pc]}]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}] - 0`);
break;
case 69:
log(`stack[${code[++pc]}] = stack[${code[++pc]}][stack[${code[++pc]}]]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}] + stack[${code[++pc]}]`);
break;
case 70:
log(`stack[${code[++pc]}] = ${code[++pc]} + stack[${code[++pc]}]`);
break;
case 71:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] << stack[${code[++pc]}]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}] | stack[${code[++pc]}]`);
log(`stack[${code[++pc]}][stack[${code[++pc]}]] = stack[${code[++pc]}]`);
break;
case 72:
log(
`stack[${code[++pc]}] = stack[${code[++pc]}].call(stack[${code[++pc]}], stack[${code[++pc]}], stack[${code[++pc]}])`,
);
break;
case 73:
log(`stack[${code[++pc]}] = stack[${code[++pc]}] >> ${code[++pc]}`);
break;
case 74:
log(`stack[${code[++pc]}][stack[${code[++pc]}]] = stack[${code[++pc]}]`);
log(`stack[${code[++pc]}][stack[${code[++pc]}]] = stack[${code[++pc]}]`);
log(`stack[${code[++pc]}][stack[${code[++pc]}]] = stack[${code[++pc]}]`);
break;
case 75:
// BRANCHING
log(`stack[${code[++pc]}] = ${code[++pc]}`);
log(`stack[${code[++pc]}][${code[++pc]}] = stack[${code[++pc]}]`);
return condJump();
case 76:
log(`stack[${code[++pc]}] = stack[${code[++pc]}].call(fnCtx, stack[${code[++pc]}])`);
break;
case 77:
log(`stack[${code[++pc]}] = stack[${code[++pc]}]`);
break;
case 78:
log(`stack[${code[++pc]}] = stack[${code[++pc]}][stack[${code[++pc]}]]`);
break;
case 79:
log(`stack[${code[++pc]}] = stack[${code[++pc]}][${code[++pc]}]`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}] >> ${code[++pc]}`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}] & ${code[++pc]}`);
break;
case 80:
log(`stack[${code[++pc]}] = ''`);
break;
case 81:
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
break;
case 82:
log(`stack[${code[++pc]}] += ${JSON.stringify(String.fromCharCode(code[++pc]))} # ${code[pc]}`);
log(`stack[${code[++pc]}] = stack[${code[++pc]}][stack[${code[++pc]}]]`);
return condJump();
}
}
}然后方便使用,写出一个命令行脚本 vm2_cli.ts:
// VM2 反编译工具
// Author: Jixun - https://jixun.uk/posts/2024/qqmusic-zzc-sign/
//
// License: CC By-SA 4.0
// See: https://creativecommons.org/licenses/by-sa/4.0/
import 'fs' from 'node:fs';
import { decompileVM2 } from './vm2'; // 引入反编译器代码
const VM_CODE = 'Xh7YHJgHOB ... 自行填写 ...';
function decodeVM(vmCode: string): number[] {
throw new Error('参见文章上方的实现');
}
const decoded = decodeVM(VM_CODE);
const explored = new Set<number>();
const actions = [] as string[];
const addr = parseInt(process.argv[2] || '3944', 10);
decompileVM2(decoded, addr, explored, actions);
// 将反编译结果写出到 dumps 目录下
fs.mkdirSync('dumps', { recursive: true });
fs.writeFileSync(`dumps/fn_${addr}.log`, actions.join('\n'));分析入口
首先在源码找到入口地址 3944,然后调用我们的反编译器:
pnpm exec node -r ts-node/register/transpile-only vm2_cli.ts 3944
得到反编译结果 dumps/fn_3944.log:
loc_3945: # op:2
stack[9] = CREATE_FUNCTION_VM2(entrypoint=3, ^args, length=1)
loc_3950: # op:46
stack[8] = CREATE_VM1_FN(4156, ^args, length=0)
loc_3955: # op:76
stack[10] = stack[9].call(fnCtx, stack[8])
loc_3959: # op:14
stack[8] = fnCtx
loc_3961: # op:1
RETURN stack[8]
转换成 JavaScript 大概如下:
stack = [];
fn_3 = stack[9] = CreateVM(3, []);
fn_4156 = stack[8] = CreateVM(4156, []);
stack[10] = fn_3(fn_4156);
return fnCtx; // undefined
基本上没啥好看的。不过可以看到它执行了地址为 3 的函数,进去看看…
pnpm exec node -r ts-node/register/transpile-only vm2_cli.ts 3
看起来一切正常,直到我们阅读 loc_0031 时,可以发现奇怪的地方:
loc_0031: # op:80
stack[10] = ''
loc_0033: # op:27
stack[17] = 81
loc_0036: # op:81
stack[10] += "f" # 102
stack[10] += "u" # 117
stack[10] += "n" # 110
loc_0043: # op:35
stack[10] += "c" # 99
loc_0046: # op:48
stack_6.vm_code[50] = stack[17]
loc_0050: # op:59
stack[10] = stack[116][stack[10]]
stack[105] = stack[10][111]
loc_0057: # op:39
stack[10] += "n" # 110
根据上下文来推断,stack[10] 的值应当为 function 才对,用来判断变量的类型;实际上却缺少了中间的 tio 字样。
如果你有接触过 自更改代码,你会发现它做了相同的事情,动态修改后续的指令:
loc_0033: # op:27
stack[17] = 81
# ... 略 ...
loc_0046: # op:48
stack_6.vm_code[50] = stack[17] # 81
因此我们在调用反编译器之前,也需要打上对应的补丁:
const vm_code = decoded;
vm_code[50] = 81;
然后再次反编译,就能得到正确的结果了:
loc_0050: # op:81
stack[10] += "t" # 116
stack[10] += "i" # 105
stack[10] += "o" # 111
如此反复进行修正,最终 fn_3 整理后的代码如下,应该是判断当前打包环境的代码用来导出函数:
loc_0004: # op:28
stack[13] = stack_4.arguments[0] # fn_4156
stack[12] = typeof define
stack[10] = "function"
stack[15] = typeof window.define === "function"
if (stack[15]) {
goto: loc_5056 # skip
} else {
goto: loc_0000 # go
}
loc_0000: # op:47
if (stack[15]) {
goto: loc_1837
} else {
goto: loc_0461 # go
}
loc_0461: # op:8
stack[9] = stack[13].call(fnCtx) ' VM1: fn_4156, loc_4157
# => fn_4156() = configure window._getSecuritySign
loc_0464: # op:14
loc_0466: # op:27
loc_0469: # op:48
stack[11] = fnCtx # undefined
stack_6.vm_code[473] = 1
loc_0473: # op:1
RETURN stack[11]
继续查看 fn_4156,重要的部分标注如下:
loc_4184: # op:46
| PUSH_ARG_VM1: stack[26]
stack[24][0] = stack[30] = CREATE_VM1_FN(6776, ^args, length=1)
# fn_6776 = class sha1(unknown: bool);
loc_4194: # op:46
| PUSH_ARG_VM1: stack[24]
stack[43][0] = stack[30] = CREATE_VM1_FN(5769, ^args, length=1)
# fn_5769 = sha1(text: str) -> str;
# 包装了一下的 `sha1` 方法
fn_5769 = (arg0: string) => {
const inst = new fn_6776(true);
inst.update(arg0);
return inst.hex();
}
# 提示: 本地调试的时候可以主动调用该函数。
# 对比和标准 SHA1 一致,就没继续看了。
loc_2211: # op:65
fn_6776.prototype.update = fn_3901
fn_6776.prototype.finalize = fn_6859
fn_6776.prototype.hash = fn_4632
fn_6776.prototype.hex = fn_2554
fn_6776.prototype.toString = fn_6776.prototype.hex
loc_2357: # op:46
| PUSH_ARG_VM1: stack[43] # [fn_5769]
| PUSH_ARG_VM1: stack[33] # [world.window]
stack[10] = CREATE_VM1_FN(5328, ^args, length=1)
stack[10] = fn_5328
loc_2367: # op:28
stack[10] = stack[33][0] # world.window
stack[39] = '_getSecuritySign'
stack[10][stack[39]] = stack[8]
world.window._getSecuritySign = fn_5328 # 导出
RETURN undefined
还记得引导代码的这部分吗?
var i = window._getSecuritySign;
delete window._getSecuritySign;
exports.default = i;
看来已经找到真正的入口了,就是 fn_5328。
分析 _getSecuritySign
和之前一样,慢慢的打补丁然后分析。
完整的补丁列表如下:
const vm_code = decoded;
vm_code[50] = 81;
vm_code[473] = 1;
vm_code[4240] = 25;
vm_code[3466] = 63;
vm_code[5754] = 81;
vm_code[6008] = 38;
vm_code[427] = 77;
vm_code[1211] = 81;
// 5769
vm_code[5835] = 1;
vm_code[457] = 47;
vm_code[4108] = 47;
vm_code[1211] = 81;
vm_code[6696] = 47;
vm_code[6811] = 47;
// stack_6.vm_code[6456] = 74 // never exec
vm_code[6584] = 5;
vm_code[2530] = 38;
// vm_code[2482] = 59 // never exec
vm_code[3480] = 7;
// vm_code[5294] = 1; // never exec
// fn_6776
vm_code[1743] = 1;
vm_code[3984] = 78;
对 fn_5328 反编译,简化后的代码如下:
loc_5674: // op:28
loc_5678: // op:76
stack[38] = fn_5769
stack[127] = fn_5769.call(fnCtx, stack[88]) # sha1
stack[38] = stack[127].toUpperCase() # sha1_hex_upper
# 检查是否为 Headless 浏览器
loc_1133: # op:16
stack[95] = true
stack[71] = stack[186].call(stack[189], stack[134])
isHeadless = stack[71] = /Headless/i.test(navigator.userAgent)
loc_1257: # op:47
stack[154] = isHeadless
validDomains = stack[95] = ['qq.com','joox.com','tencentmusic.com','wavecommittee.com','kugou.com','kuwo.cn']
loc_6077: # op:78
stack[186] = window.__qmfe_sign_check # 网页端该值为 undefined
stack[98] = __qmfe_sign_check === 1
if (stack[98]) { // always undefined
goto: loc_4733
} else {
goto: loc_4098 // => always this path
}
loc_4098: # op:27
stack[98] = stack[104] # typeof location === 'object'
if (stack[98]) { // true
goto: loc_6138 => loc is object
} else {
goto: loc_0291
}
loc_6138: # op:63
notHeadlessBrowser = stack[98] = !isHeadless
if (notHeadlessBrowser) {
goto: loc_3963 # => not headless
} else {
goto: loc_4733
}
loc_3963: # op:9
# ... 省略,最终跳转到 loc_3993 ...
# 检查域名
loc_3993: # op:67
fn_601 = (arg0) => global.location.host.indexOf(arg0) > -1
stack[98] = validDomains.some(fn_601)
stack[186] = 16
stack[134] = 19
stack[95] = ''
offset_part1 = stack[95] = [ 23, 14, 6, 36, 16, 40, 7, 19 ]
fn_3487 = (offset) => sha1_hex_upper[offset];
hash_part_1 = stack[139] = offset_part1.map(fn_3487)
hash_part_1 = stack[153] = hash_part_1.join('')
loc_4842: # op:56
stack[186] = 12
offset_part_2 = stack[153] = [16, 1, 32, 12, 19, 27, 8, 5]
# 同 offset_part_1 的操作,略
# 第三部分
loc_5037: # op:77
stack[186] = 121
stack[189] = 179
hash_scramble_values = stack[87] = stack[38] =
[ 89, 39, 179, 150, 218, 82, 58, 252, 177, 52,
186, 123, 120, 64, 242, 133, 143, 161, 121, 179]
# for loop
loc_0453: # op:48
stack_6.vm_code[457] = stack[38] = 47
tmpArr = stack[48] = stack[18] = []
i = stack[144] = 0
stack[181] = i
stack[112] = i < 20
loc_0457: # op:47
if (stack[112]) {
goto: loc_5200 # loop body
} else {
goto: loc_6592 # loop complete
}
loc_5200: # op:60
# stack[43] = [sha1_hex_upper]
# stack[85] = hexRevTable {"0":0, ..., 'F': 16}
# stack[87] = hash_scramble_values
# stack[48] = tmpArr
hi8 = hexRevTable[sha1_hex_upper[i*2]]
lo8 = hexRevTable[sha1_hex_upper[i*2+1]]
value = hi8 * 16 + lo8
value ^= hash_scramble_values[i]
tmpArr.push(value)
loc_4053: # op:77
stack[112] = ++i < 20
loc_4068: # op:47
if (stack[112]) {
goto: loc_5200 // loop again
} else {
goto: loc_6592 // end of loop
}
loc_6592: # op:53
# 略,又臭又长的 base64 编码代码
loc_0912: # op:77
b64_encoded = stack[80] = stack[134] # 最终的 base64 编码后的内容
loc_0978: # op:30
# 删除 Base64 的特殊符号
stack[38] = RegExp("[\\/+]", 'g')
stack[186] = ''
stack[189] = b64_encoded.replace(/[\\/+]/g, '')
# 拼接签名
loc_0994: # op:38
stack[189] = 'zzc'
stack[186] = 'zzc' + hash_part_1
stack[189] = 'zzc' + hash_part_1 + b64_encoded_part
stack[186] = 'zzc' + hash_part_1 + b64_encoded_part + hash_part_2
sign = stack[46] = stack[186]
# 清理内存?
loc_1018: # op:53
stack[55] = stack[116] = stack[80] = stack[74] = stack[162] = stack[8] = false
# 结果转小写
loc_1035: # op:38
sign = stack[134] = sign.toLowerCase()
RETURN sign
呼,终于将整个程序的过程看完了。
本身并不是很复杂的函数,经过虚拟化混淆、膨胀后,分析起来可真不容易。
重新实现
将上述代码整理,最终的 TypeScript 实现(使用 Node):
import crypto from 'node:crypto';
// Author: Jixun - https://jixun.uk/posts/2024/qqmusic-zzc-sign/
// License: MIT License
const hexRevTable: Record<string, number> = {};
for (let i = 0; i < 16; i++) {
hexRevTable[i.toString(16)] = i;
}
function hashText(text: string): string {
const sha1Inst = crypto.createHash('sha1');
sha1Inst.update(Buffer.from(text, 'utf-8'));
return sha1Inst.digest().toString('hex').toUpperCase();
}
const PART_1_INDEXES = [23, 14, 6, 36, 16, 40, 7, 19];
const PART_2_INDEXES = [16, 1, 32, 12, 19, 27, 8, 5];
const SCRAMBLE_VALUES = [89, 39, 179, 150, 218, 82, 58, 252, 177, 52, 186, 123, 120, 64, 242, 133, 143, 161, 121, 179];
function pickHashByIdx(hash: string, indexes: number[]) {
return indexes.map((idx) => hash[idx]).join('');
}
export function sign(text: string): string {
const sha1 = hashText(text);
const part1 = pickHashByIdx(sha1, PART_1_INDEXES);
const part2 = pickHashByIdx(sha1, PART_2_INDEXES);
const part3 = SCRAMBLE_VALUES.map((scramble, i) => scramble ^ parseInt(sha1.slice(i * 2, i * 2 + 2), 16));
const b64Part = Buffer.from(part3)
.toString('base64')
.replace(/[\\/+=]/g, '');
return `zzc${part1}${b64Part}${part2}`.toLowerCase();
}结语
相比上个版本(签名前缀为 zzb),本次更新有很多改变:
zzb是相对传统的堆栈虚拟机,字节码操作都是基于栈底的几个参数进行操作;zzc则是全程指定要访问/操作的堆栈位置。zzb的每一个操作码 (OpCode) 都是对应一个操作;zzc则是一个操作码对应多项操作;- 透过堆栈末尾来观察规律变得更加困难,但利好反编译分析。
zzb的 MD5 计算之前是单独放在另一个未进行 VMP 处理的函数,这次则是换成 SHA1 一起塞进去了。zzc使用的架构允许代码利用自修改机制来动态补丁代码,对静态分析有一定的挑战。
不过弱点依然存在:
- 只要愿意,让虚拟机每解释一条指令就打印堆栈,还是可以大概看出来代码在干什么。
- 不过这个版本内嵌了个 SHA1 函数进去,如果只是观察 trace 会很难分析出它在干嘛…
- 生成最终签名的步骤和上个版本有很多相似,只是挑选的常数有所不同。
感觉基于 JavaScript 方案的强度相比编译后的 WebAssembly 始终会差一些,不过自修改代码应该也是 Wasm 所做不到的。
分析的时候有些地方连蒙带猜,例如 fn_6776 函数是直接尝试调用看看是不是标准的 SHA1 算法,确认后就可以跳过不看了(因为发现了初始化相关常数)。
QQ 音乐用的应该是 js-sha1 库,看代码能看到一些熟悉的成员命名。
附录
A.1 补环境调用
环境检测没有很严格,一个简单的补环境方案如下:
var GLOBAL = {
window: null,
_getSecuritySign: null,
__qmfe_enccgi_check: 1, // ag-1 代码会检测到该值,用于跳过域名校验
hello: 'mocked global',
RegExp,
navigator: { userAgent: 'Definitely Chrome (123.4)' },
location: { host: 'y.qq.com.jixun.uk' },
};
GLOBAL.window = GLOBAL;
然后替代 n(80) 为 GLOBAL 传递进去即可。
初始化后,导出 GLOBAL._getSecuritySign 做 zzcSign 方法使用即可。
此外还有个“官方后门”,设置 GLOBAL.__qmfe_sign_check 为 1 后能跳过 userAgent / location 校验,或许是为了方便内部的自动集成测试?
或是补丁虚拟机代码的 QsQB9AIC 为 IMQBIMQB 一样可以达成跳过环境检测的效果。
A.2 动态调试 / trace
将分发代码做少许更改即可:
for (;;) { // 原来的 for 循环加上花括号
const opcode = code[++pc];
let recPC = pc;
let recOpCode = opcode;
// 下面这行可下条件断点,如 `pc === 4`
console.log(`VM2 ${loc(pc)}/op:${opcode}`);
switch (opcode) { /* ... 略 ... */ }
}
IDE 通常可以设置条件断点,例如将条件设为 pc === 4 即可在执行该地址指令时断下。
A.3 NPM 包
打包上传到 npm 了,可以直接安装 @jixun/qmweb-sign 使用。
项目的代码仓库在 GitHub: jixunmoe/qmweb-sign。
使用也很简单:
// ModuleJS, bundler, etc
import { zzcSign, decodeAG1Response, encodeAG1Request } from '@jixun/qmweb-sign';
// CommonJS
const { zzcSign, decodeAG1Response, encodeAG1Request } = require('@jixun/qmweb-sign');
// 示例代码,根据需要改写。
async function example() {
const payload = JSON.stringify({ /* 填写你的请求载荷 */ });
const body = await encodeAG1Request(payload);
const sign = zzcSign(payload);
const url = `https://u6.y.qq.com/cgi-bin/musics.fcg?_=${Date.now()}&encoding=ag-1&sign=${sign}`;
const res = await fetch(url, {
body,
method: 'POST',
headers: { /* 填写你的请求头 */ },
});
const buffer = await res.arrayBuffer();
const respText = decodeAG1Response(buffer);
return JSON.parse(respText);
}
※ npm 包从 v2.0.0 开始提供 ag-1 加密方案支持。
A.4 其它语言的实现
实验了下其它语言的实现,Python 基本的东西都有,写起来也挺顺手的。
- Python 版本:
zzc_sign.py、ag1_cipher.py - Rust 版本:
qmweb-rust-wasm/src/lib.rs
※ Rust 实现停留在 v1.0.4 版本,不再更新。
A.5 订正记录
2025.06.11
发现网页端从大概自 2025 年 5 月末引入了一个新的 ag-1 加密方案,服务器根据请求参数选择是否启用;zzc 签名方案未更改,在启用 ag-1 的情况下对原始数据进行加密。
用了类似的 JSVMP 混淆方案,照着本文的思路进行拆解即可。但因为用上了异步,逆向时会麻烦一点,因此这里就不放上拆解过程了。
推荐读者跟着本文一步一步处理,可以利用重新实现的代码进行对照参考。
2025.06.28
订正文章错字;微调文章排版。
